我自己也在做弹幕游戏,最近看到了一个非常优秀的弹幕游戏开源库 DanmakU,我学习了一下,然后将其加入到了我自己的项目中,在这里就讲一下那个库里一些设计上比较好的地方。
1. 说说开学之后的生活
开学到现在是刚好三周,在这三周里,我自己感觉自己的学习状态有很大进步。
首先体现在作息时间上。开学以来,除了周末,我平时都是 11.30 左右睡觉,早上 7.20 起床,很规律。
然后呢,平时的学习也很好。每天都是在学习,看书。课余时间看书比较多,所以游戏就玩得少了,之后的两周,应该会画比较多的时间在玩游戏上,比较少的时间在看书上。
看书方面的话,看了《雍正王朝 上中下》,花了三周,终于断断续续的看完了这本大部头,其中第三部还读了两遍,还是很有收获的吧。
玩游戏的话,倒是没有玩什么新游戏,平时都是很闲的时候玩玩大型开发世界游戏养老,没什么好说的。
2. 初始设计 – 对象池
弹幕游戏的一个重要的特点是会在同一时刻生成大量的子弹,也会在同一时间销毁大量子弹。就像粒子一样。如果处理不当的话,会一下子造成许多内存碎片。
我最初的实现方法,就是用到了对象池。
- 每当要生成一个新的子弹的时候,现在池中找,如果没有找到,就 Instance 一个,然后把这个新生成的子弹放入池中;如果找到了,就把池中的那个子弹拿出来,SetActive(true)。
- 每当要销毁一个子弹时,将这个子弹 SetActive(false) ,然后把这个子弹放入池子中。
这样的池子显然不太好。首先,如果池子里初始是空的话,要一瞬间大量生成子弹的话,就会在一瞬间大量 Instance 很多子弹,会比较卡。其次,因为每个子弹都有其独特的脚本、属性,因此在生成子弹的时候,无法批量生成。
|
|
上面展示了批量生成和单个生成的不同。批量生成的话,是在内存中拿出一块连续的空间,因此就会相当快。单个生成的话,相当于在内存中分配 count 次单个子弹的内存空间,就会很慢,同时也会造成不少内存碎片。
3. 初始设计 – 子弹移动脚本
在我之前的设计中,每个子弹由一个协程来控制其运动轨迹。似乎大部分弹幕游戏都是这样设计的(包括但不限于):
每个子弹一个协程来控制,这样显然就会有性能上的问题。
4. 初始设计 – 子弹渲染
一般来说,每个子弹都是一个 SpriteRenderer 来渲染,如果用的 SpriteRenderer 有一点点不一样的话,那么就是不能在同一个 DrawCall 里处理的。这样,如果子弹多了、复杂了,就会有很多 DrawCall,会对 GPU 造成很大影响。
5. 优化
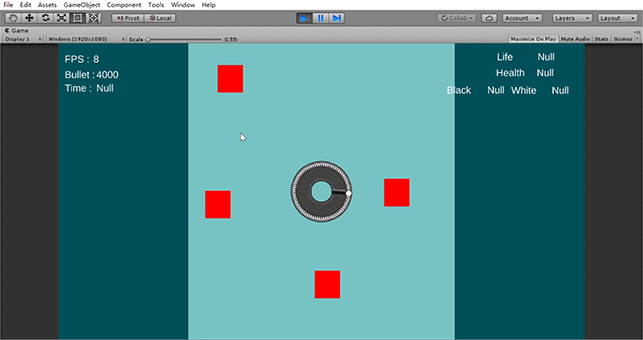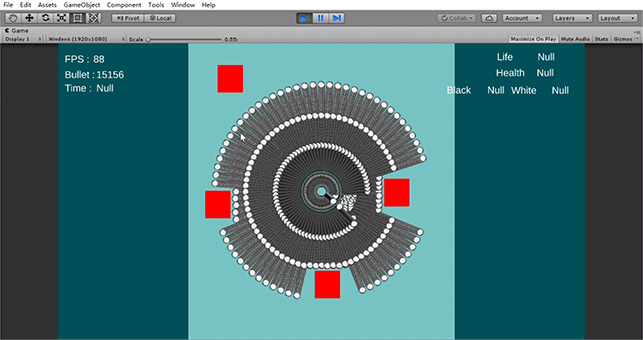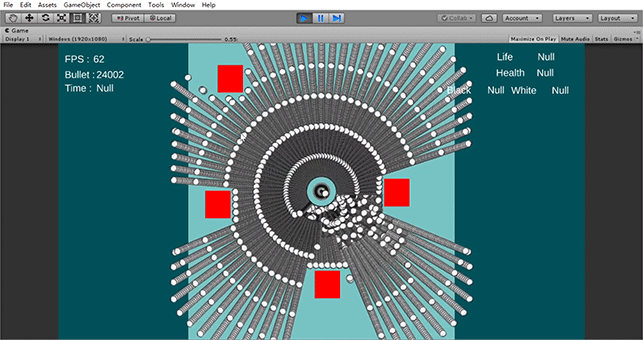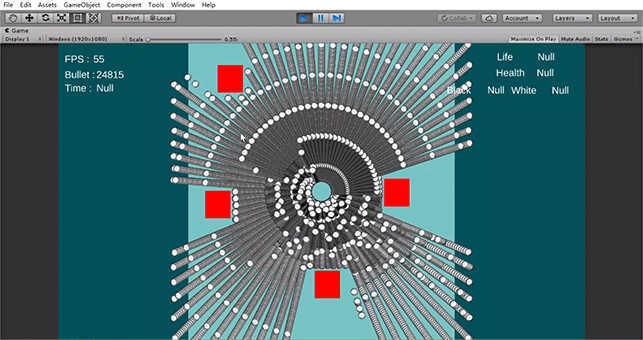
主要的优化手段就是三个:内存连续的对象池、多线程处理子弹移动、GPU Instance 去进行子弹渲染。
首先,子弹不用使用 GameObject 了,而是将子弹的各个信息拿出来,单独做成一个对象池。例如:
|
|
这样,使用了值类型的数组,在内存中就一定是连续的了。然后,如果保证前 Active 个数据都是可使用的话,那么添加和删除一个数据都是十分简单的:
|
|
完全不产生任何内存碎片,而且时间空间复杂度均为 O(1)!
在渲染的时候,利用子弹的这些数据(位置、旋转、颜色),直接强制 Unity 用 GPU-Instance 去渲染子弹,这样也可以大大减少 DrawCall。
最后,在控制子弹移动的时候,可以利用 Unity 2018.1 的多线程 API,对于同一发射点的子弹用多线程进行统一更新。由于子弹的信息在内存中是连续排布的(对象池),因此更新时,除了能够利用多线程的多核去跑之外,还可以提高 CPU 的缓存命中率,这样,大大提高了运算速度。
我自己在测试的时候,同时跑 400,000 个子弹,帧率大概在30帧左右,CPU 占用率是 50%。